A Microservice Architecture for Real-Time Data Collection
This article champions an event-driven microservice architecture to overcome the data lag of traditional monolithic, batch-processing systems in retail and finance.

By Clive Dsouza
Senior Software Engineer, Intuit CreditKarma
Clive Dsouza is a seasoned technology professional with over a decade of experience spanning retail, insurance, banking, education, and IT. He specializes in developing scalable, high-performance software solutions using React, TypeScript, GraphQL, and cloud-based architectures, mainly front-end and back-end development.
Abstract:
This article proposes an event-driven microservice architecture designed to overcome the limitations of traditional monolithic, batch-processing data collection systems prevalent in the retail and financial sectors. These legacy systems are prone to significant data lag, leading to issues like inventory miscalculations and delays in fraud detection. The proposed architecture utilizes open-source tools, like Apache Kafka for event streaming and Apache Avro for optimized data serialization, to achieve near-real-time data collection with very low latency. By implementing decoupled, specialized microservices, the system ensures high throughput, fault tolerance, and independent scalability, enabling immediate data analysis and action. The result is a robust framework capable of managing the high volume and velocity of a large-scale digital ecosystem, providing instant operational insights and superior system resilience compared to conventional methods.
I: INTRODUCTION
Major US retailers and financial institutions often rely on traditional data collection systems that gather data from the front end, ingest it through batch processing, and deliver it to consumer storage platforms like GCP or AWS for analytical purposes.
In data-intensive retail or financial domains, these monolithic and batch-processing approaches commonly suffer from significant data lag. This leads to problems such as inventory miscalculations and delayed fraud detection due to the time it takes for data to reach downstream systems.
A practical solution is an event-driven microservice architecture that collects and processes data in near-real-time using widely available open-source tools.
II: EVENT-DRIVEN FRAMEWORK
This section provides an overview of the architecture and its core components.
Once data is sent from the front end, a lightweight ingestion system (e.g., built in Node.js) can handle incoming requests, validate for errors, and forward it to the next layer with minimal delay. A key element is data serialization/deserialization using Apache Avro, which ensures efficient encoding and decoding. An event-streaming platform like Apache Kafka provides a low-latency, fault-tolerant, high-throughput producer-consumer pipeline for real-time data flow. This data can then feed into big data systems like HDFS.
Subsequently, another ingestion tool like Logstash can ingest the data, apply transformations, and store it in a destination such as Elasticsearch—all with sub-millisecond to low-millisecond latency—making it immediately available for analysts to query in real-time using tools like Kibana.
Events are differentiated by their source (e.g., item details page, digital checkout cart, self-checkout terminals, inventory scanners). This allows multiple decoupled microservices to generate events using a shared base Avro schema plus child schemas tailored to specific use cases. Each microservice independently handles deduplication and data scrubbing, ensuring payloads adhere to organizational guidelines.
A separate set of microservices consumes events from the Kafka stream and applies specific business logic or transformations.
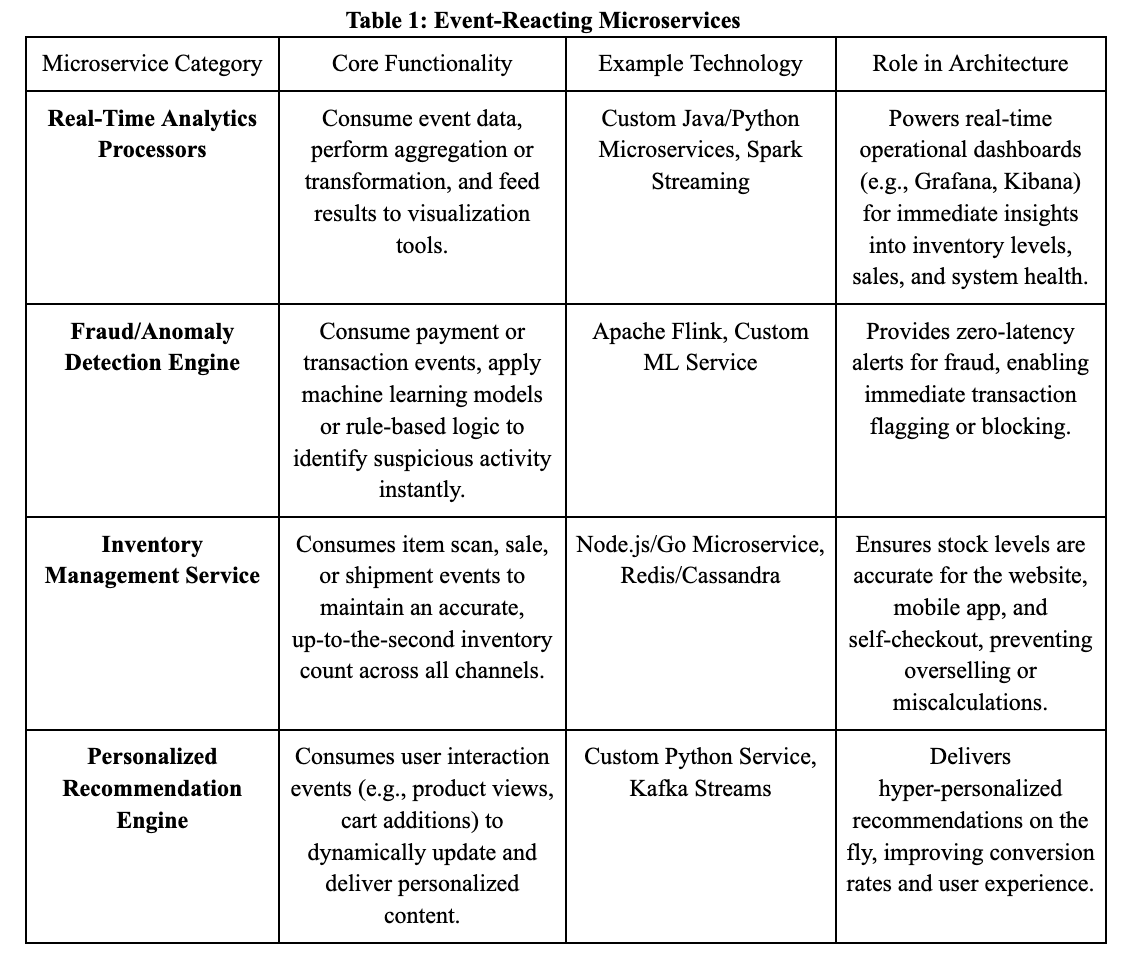
These consuming microservices are independently deployable and scalable. By subscribing to specific Kafka topics, they receive only relevant event data, maximizing decoupling and performance.
III: IMPLEMENTATION IN A LARGE SCALE ENVIRONMENT
This microservice architecture can be successfully deployed in a major US retailer's digital ecosystem, handling data from thousands of simultaneous endpoints—including e-commerce platforms, mobile apps, and in-store POS systems. Its distributed nature is essential for managing high data volume and velocity.
Key implementation strategies include:
- Deployment Model: Containerize each microservice with Docker and orchestrate via Kubernetes for rapid deployment, configuration, and health monitoring across the cluster.
- Schema Enforcement: Maintain strict governance over Apache Avro schemas using a dedicated Schema Registry to ensure producers adhere to contracts, preventing downstream failures and preserving data integrity.
- Topic Segregation: Organize events into specific Kafka topics (e.g., user-cart-updates, inventory-scans, payment-attempts). This reduces load on individual topics and allows consumers to subscribe only to relevant streams, optimizing resource use.
IV: INDEPENDENT SCALABILITY AND PERFORMANCE
During peak events like Black Friday or Cyber Monday, the architecture enables independent scaling of components without affecting the rest of the system.
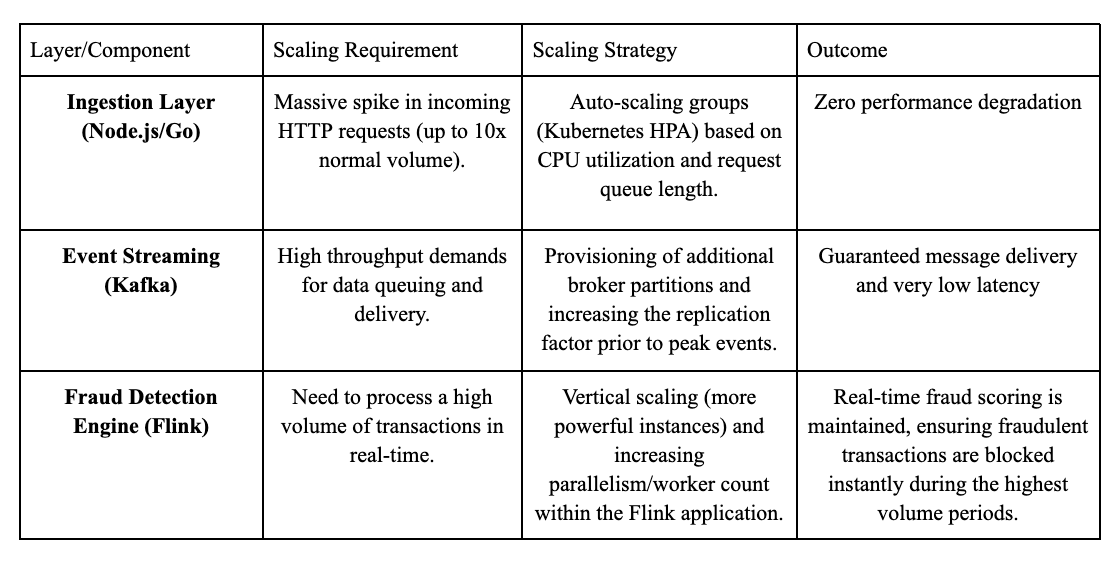
V: SYSTEM RESILIENCY AND FAULT TOLERANCE
The event-driven, decoupled design greatly enhances resiliency—failures in one service are isolated and do not cascade.
- Handling Service Failure: If a consumer fails, it stops processing its Kafka topic. Events remain safely queued in Kafka (with high retention and replication). Upon restart/redeployment, the service resumes from its last offset and clears the backlog without data loss.
- Decoupled Operation: Even if one service is down, others (e.g., Fraud/Anomaly Detection or Real-Time Analytics) continue consuming their streams and performing core functions uninterrupted.
- Consumer Idempotency: All consumers are designed to be idempotent—reprocessing the same event causes no duplicate effects (e.g., no double inventory deductions)—via transaction IDs and state management, ensuring accuracy during recoveries.
VI: CONCLUSION
This event-driven microservice architecture represents a significant advancement over traditional batch processing by minimizing data latency and maximizing resilience.
Its core strengths are near-real-time data delivery and extreme decoupling. Shifting to a Kafka-based event-streaming backbone with specialized, independent microservices makes data instantly actionable. This supports time-sensitive operations—like real-time inventory updates and rapid fraud detection—in low-millisecond ranges, directly addressing retail challenges such as inventory errors and delayed security responses. Docker/Kubernetes deployment and idempotent consumers further provide exceptional fault tolerance and scalability, allowing services to scale independently during spikes or recover seamlessly.
This real-time foundation enables advanced future capabilities:
- AI-Driven Web Components: Immediate user interaction data (e.g., clicks, views, scroll depth) from event streams can feed real-time ML models. Outputs can generate dynamic UI components based on in-session behavior using SSR frameworks like Next.js, optimizing conversions instantly.
- Dynamic Personalized Recommendations: Transaction and browsing events feed a real-time recommendation microservice for suggestions updated on the latest activity, cart contents, and inventory—moving beyond static, cached recommendations.