


Venice AI Launches Verifiable End-to-End Encryption
Venice AI introduces TEE and E2EE modes that make AI privacy cryptographically verifiable — turning trust into math and giving users proof, not promises.


For the first time, an AI platform is offering cryptographically verifiable privacy — not promises, not policies, but math. Venice's new TEE and E2EE modes let any third party independently confirm your prompts were never seen by anyone.
Every major AI company stores your conversations. Every prompt, every response — saved, analyzed, and accessible to employees, third-party contractors, hackers, and government subpoenas. This is the default state of AI in 2026. Venice AI, the open-source-first AI platform founded by Erik Voorhees, has been building against that assumption since day one. Today, they took their most significant step yet.
Venice just shipped two new privacy modes — Trusted Execution Environments (TEE) and End-to-End Encryption (E2EE) — that move AI privacy from the realm of contractual promises into the realm of cryptographic proof. Vires in numeris.
"Ubiquitous mass surveillance is an unethical foundation on which to build society." — Venice AI, on the principle behind their architecture
Four Modes, One Principle
Venice has reorganized its entire privacy architecture into four explicit modes. The framing is deliberate: users deserve to understand exactly what protection they're choosing before they start a conversation. Here's how each mode works:
Introducing our four Privacy Modes on Venice.
— Venice (@AskVenice) March 18, 2026
Every AI model now falls into one of four categories, each with different protections and trade-offs. You choose based on what matters most for each conversation. pic.twitter.com/pQANxX4DUX
Anonymous:
Venice proxies requests to frontier model providers — GPT, Claude, Gemini, Grok. Your IP and identity are masked from the provider. But you should assume the provider stores your content. Privacy here is identity-level, not content-level.
Private (Default):
Inference runs on Venice-controlled GPUs or zero-data-retention partner infrastructure. No prompt or response is stored anywhere but your device. Privacy is enforced by contract — you're trusting Venice and its partners to honor their commitments.
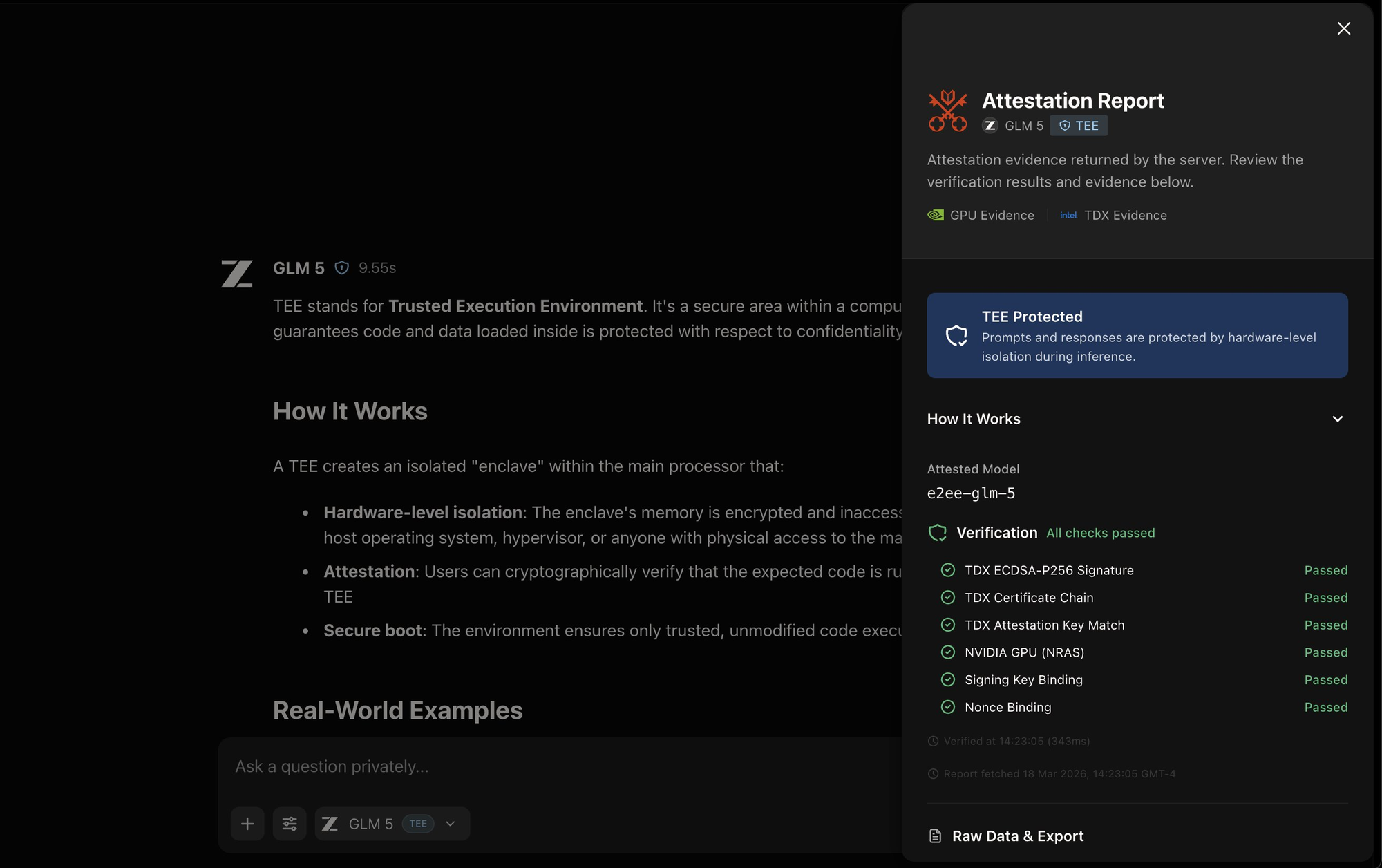
TEE (PRO):
Inference runs inside a hardware-isolated secure enclave. The GPU provider cannot access your prompts. Verified by remote attestation — a cryptographic certificate tied to the hardware itself that any external party can independently validate. (Hardware -verified)
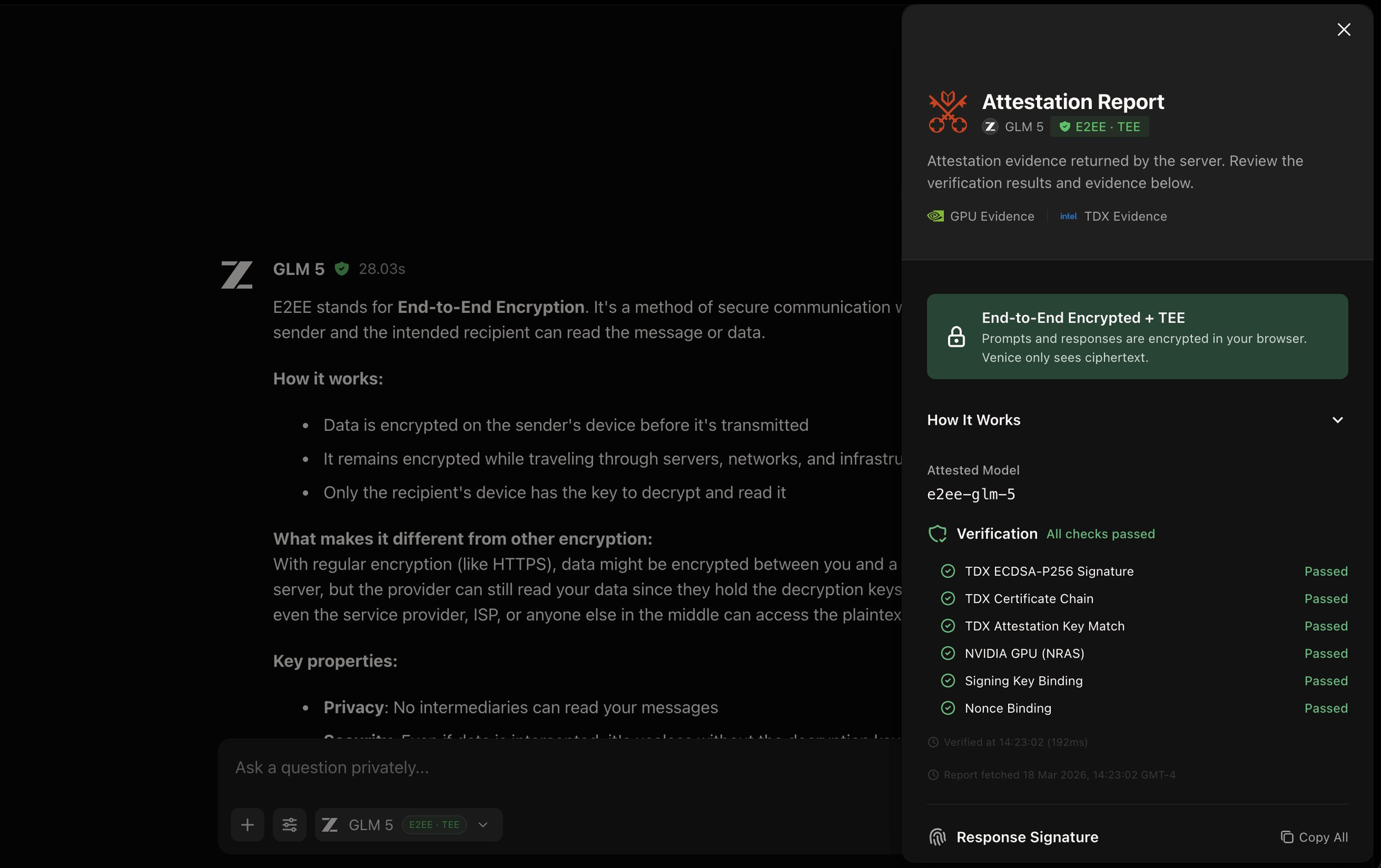
E2EE (PRO):
Your prompt is encrypted on your device before it leaves. It stays encrypted through Venice's infrastructure. It is only decrypted inside a verified hardware enclave. Neither Venice nor the GPU provider can see your data at any point.
(Cryptographically verifiable)
The crucial distinction: Anonymous and Private modes are trust-based — you're relying on Venice's policies and contracts. TEE and E2EE modes are math-based. The security is enforced by hardware and verified through cryptographic attestation. You don't have to trust anyone.
What "Verifiable" Actually Means
The word "verifiable" is doing a lot of work here, and it's worth unpacking precisely what Venice means by it. When a model runs inside a TEE, the hardware itself generates a signed cryptographic certificate — called an attestation quote — that contains measurements (hashes) of the exact code running in the enclave. That certificate is bound to the hardware.
Venice builds its inference image with reproducible builds. Anyone can clone the repository, run the build, and produce the exact same measurements. Every release is signed and published to a public transparency log. This means you can verify, without Venice's involvement, that the code you see in the repo is the code running on the GPU processing your prompt.
Every TEE and E2EE response on Venice now displays a verification icon. Clicking it opens the full attestation report — showing which hardware attestation checks passed, the exact model attested, and timestamps. This is the receipt.
The Infrastructure Partners
TEE and E2EE inference on Venice is currently operated by two external partners: NEAR AI Cloud and Phala Network — both projects with deep roots in the open and decentralized technology ecosystem. Venice has published technical documentation from both providers covering E2EE implementation, attestation verification, and the underlying dstack architecture.
Eleven models currently support both TEE and E2EE modes, including Venice Uncensored 1.1, GLM 5, Qwen3.5 122B, Gemma 3 27B, GPT OSS 20B, and GPT OSS 120B. More are coming. TEE and E2EE are Venice Pro features.

Venice's launch lands at a moment when the private AI space is quietly becoming a serious field. The most technically notable parallel effort is Confer, the encrypted AI platform built by Signal Protocol creator Moxie Marlinspike. Confer takes a similar architectural approach — combining confidential computing with passkey-derived encryption so that not even Confer itself can access user conversations.
What makes Confer worth watching is both its technical pedigree and news: Marlinspike announced in a blog post he'll work to integrate Confer's privacy technology into Meta AI — the same way he worked with Meta a decade ago to bring end-to-end encryption to WhatsApp for two billion people. If that integration succeeds at scale, it would represent the largest deployment of private AI inference ever attempted.
Confer's Approach:
Like Venice's E2EE mode, Confer runs LLM inference inside a confidential VM using hardware-enforced isolation. User prompts are encrypted from device directly into the TEE via Noise Pipes — the host machine provides CPU and power but never sees plaintext. Attestation is handled through dm-verity over the full root filesystem and a public transparency log for reproducible builds. The core design principle: the server is an endpoint in the conversation, but the people running it cannot read what's in it.
Both projects are doing the actual cryptographic work — and notably, both depend on open-weight models to do it. You cannot run a closed-source model inside a TEE with verifiable attestation. The privacy guarantees only hold because the code is auditable. That's not a coincidence.
"You don't need to protect what you don't have." — Venice AI, on their foundational design principle



